Micro services and Fault injection testing
With the evolution of micro services, software development world has changed for ever. With a smaller code to maintain, clearer contract to follow and ability to push the components to production independently, developers’ life has become much easier.
With smaller code at hand, it also brought opportunities to experiment with newer technology stacks/architectural patterns e.g. Asynchronous message based communication, communication over JSON(Rest), in memory caching and more.
Looking at all these, it paints a very rosy picture of how a highly available and scalable enterprise software will look like and how it fits in agile methodology of delivering features faster and at frequent intervals.
While most of it is true, faster delivery of end to end features are still alluding most of the development teams and high availability doesn’t come for free even in the world of micro services.
What’s stopping teams from delivering end to end features faster? Why availability is still a concern? Let’s take a closer look.
Is development a bottleneck any more? What micro services and the newer technology stacks promised is to cut down on the the development effort significantly and it surely does. But does it also cut down other parts of the sdlc phase?
While it simplified the development cycle, micro services added a significant overhead on monitoring, identifying the failure point and testing in general. Challenges in testing in the world of micro services
Environment setup
Each service has several dependencies now. Some of them are direct dependencies and many of them are transitive.Each team keeps on adding new features which in turn adds new dependencies for the upstream clients. Keeping a tab on someone else’s world is practically impossible. So the very first challenge is to setup an environment with all the dependencies where functional end to end test cases can run. In many cases all these services can fit and run on one single box. For such cases life is still quite manageable. There comes a times when all these services may not run on the same box because of many underlying infrastructure gotchas, e.g. Multiple services listening on the same ports, too many services to handle on one box, conflicting dependencies(Java 1.7 vs Java 1.8).
The more and more services we have, chances of getting into this mess is very high.
Negative/ resiliency testing and fault injection
The resiliency of the system comes from the fact that every part of the system is able to handle at least some reasonable level of errors and faults. Be it a downstream service unavailability, network latency, caching issues or db issues; distributed system is full of such implicit non functional requirements and corresponding handling.
Our testing can’t be completed until we do a certain level of negative/fault tolerance testing.
Setting up environment for this is even harder. Considering hundred of tests needing fault at different levels and each setup needing a whole bunch of boxes, the scenario here looks pretty scary. It won’t be an exaggeration to say that many teams/companies actually won’t have a setup to do such testing at scale.
A centralized test environment with fault injection support
The approach we are going to discuss is to add an intelligent routing component/proxy layer which can inspect the requests and forward it to the right services and if required inject the desired fault during testing.
We can have multiple instances of the same component running to make sure higher availability of the test infrastructure.
For simplicity let’s say we have 3 services providing restful endpoints for different entities. ServiceA is listening on port A and has a downstream dependency on ServiceB listening on port B which further depends on ServiceC which listens to port C.
Lets also assume we have a common header request-id which will identify the whole request flow and will be passed along in all the downstream/side stream service calls.
Test setup
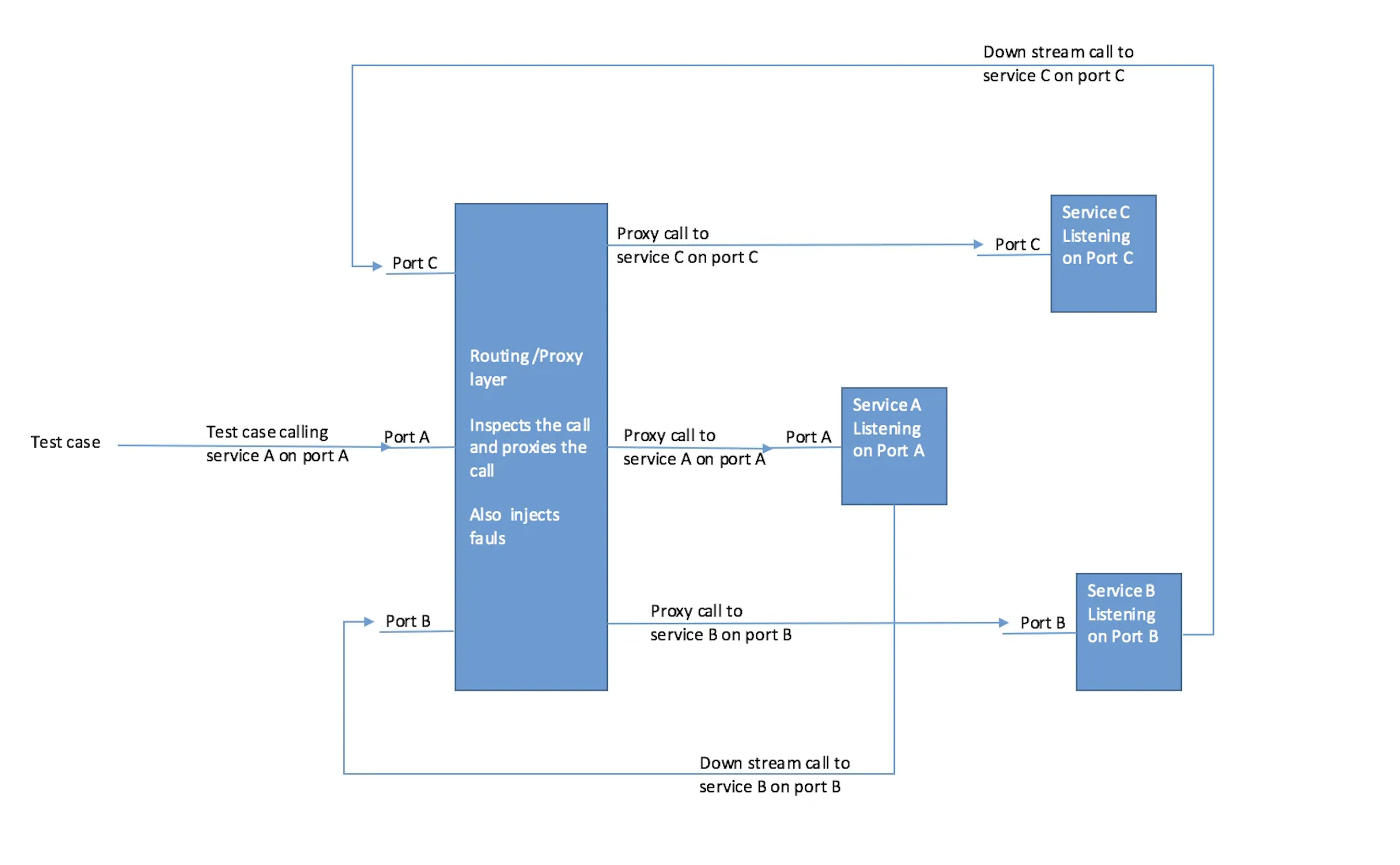
The routing/proxy component
We can use nginx+lua to setup the proxy layer. You can read more about nginx and lua here:
Pushing Nginx to its limit with Lua
definitely-an-open-resty-guide
We will be using openresty for the proxy implementation.
Requirements for the proxy:
-
Load balancing the request to different upstreams. We can have multiple instances of the services running and we can route the incoming request for the service to use one of the many instances.
-
Per request fault injection. Request-id can be used to determine and inject the necessary fault.
Load balancing
We can use Redis to store service and hosts mapping. For each request for a specific service our Lua code can get the upstream details from Redis and forwards the request in round robin fashion.
sample redis entry:
> Redis Key: service_discovery
> Sub key: 9001
> value: server1, server2 Fault injection
Basic approach: in test setup step generate a request-id and store the required fault details in a shared place which can be accessed by routing layer. Routing layer, upon receiving the request, inspects the request-id and checks against Redis if there is any fault injection required in the immediate service call. If not, then it continues as earlier, else, it parses the stored fault information and responds accordingly.
The format could look like:
> Redis Key: faultinjection
> Sub key: request_f7a7bb674caec
> value: “{\”markdown\”:{\”uri\”:[\”users\”]},\”delay\”:{\”books\”:\”10\”}}”; - Downstream failure: we can have instructions saying markdown, which will effectively cause a 500 when the flow is trying to hit the particular service.
- Delayed response: we can have instructions like delayed which will delay the response by the given amount of time in seconds.
- Mock/failed response: we can also populate the info with mock fake response from the service. For scenario where it’s difficult to replicate a failure in downstream system, this is useful for predicable result.
- In fact we can enhance this to also do record/playback for component testing. Where all downstream dependencies can be easily mocked out. Sample code:
Load Balancing:
REDIS_HOST = "127.0.0.1"
REDIS_PORT = "6379"
DEFAULT_UPSTREAM_SERVER = "127.0.0.1"
local redis = require "resty.redis"
local red = redis:new()
red:set_timeout(1000) -- 1 second
local ok, err = red:connect(REDIS_HOST,REDIS_PORT)
if not ok then
ngx.var.target = DEFAULT_UPSTREAM_SERVER
else
local key = "service_discovery"
-- Services are idenified by the port they listen to.
-- Can also be identified by service name or any other information which can be extracted from the request
local host_list_str, err = red:hmget(key, ngx.var.server_port)
if not host_list_str or host_list_str[1] == ngx.null then
ngx.var.target = DEFAULT_UPSTREAM_SERVER
else
local hosts = {}
local index = 1
-- Comma seperated host list for a given service
for value in string.gmatch(host_list_str[1], "[^,]+") do
hosts[index] = value
index = index + 1
end
-- Pick a random host, assuming randomness will also bring some form of roundrobin-ness
ngx.var.target = hosts[math.random(#hosts)]
ngx.log(ngx.ERR, "selected host is: " .. ngx.var.target)
end
endFault injection:
function has_value (tab, val)
for index, value in ipairs (tab) do
if value == val then
return true
end
end
return false
end
REDIS_HOST = "127.0.0.1"
REDIS_PORT = "6379"
DEFAULT_UPSTREAM_SERVER = "127.0.0.1"
local redis = require "resty.redis"
local red = redis:new()
red:set_timeout(1000) -- 1 second
local ok, err = red:connect(REDIS_HOST,REDIS_PORT)
local headers = ngx.req.get_headers()
local req_id = headers["request-id"]
-- Check fault injection information in redis for the request-id
if(req_id and ok) then
ngx.log(ngx.ERR, "request-id" .. req_id)
local fault_details, err1 = red:hmget("faultinjection",req_id)
if not fault_details or fault_details[1] == ngx.null then
ngx.log(ngx.ERR, "No fault details found")
else
#local operation = headers.operation
local operation = ngx.var.uri
ngx.log(ngx.ERR, "operation is: " .. operation)
local cjson = require "cjson"
local json = cjson.new()
local faults = cjson.decode(fault_details[1])
local markdowns = faults.markdown
ngx.log(ngx.ERR, "First Markdown is: " .. markdowns.uri[1])
if(has_value(markdowns.uri, operation)) then
ngx.log(ngx.ERR, "Returning from markdown: ")
ngx.exit(500)
else
ngx.log(ngx.ERR, "No markdown found for this uri continuing normally")
end
local delays = faults.delay
if delays then
local request_delay = delays[operation]
if request_delay then
ngx.log(ngx.ERR, "Delaying the request")
ngx.sleep(tonumber(request_delay))
else
ngx.log(ngx.ERR, "No delay found for this uri continuing normally")
end
else
ngx.log(ngx.ERR, "No delay found")
end
end
end